
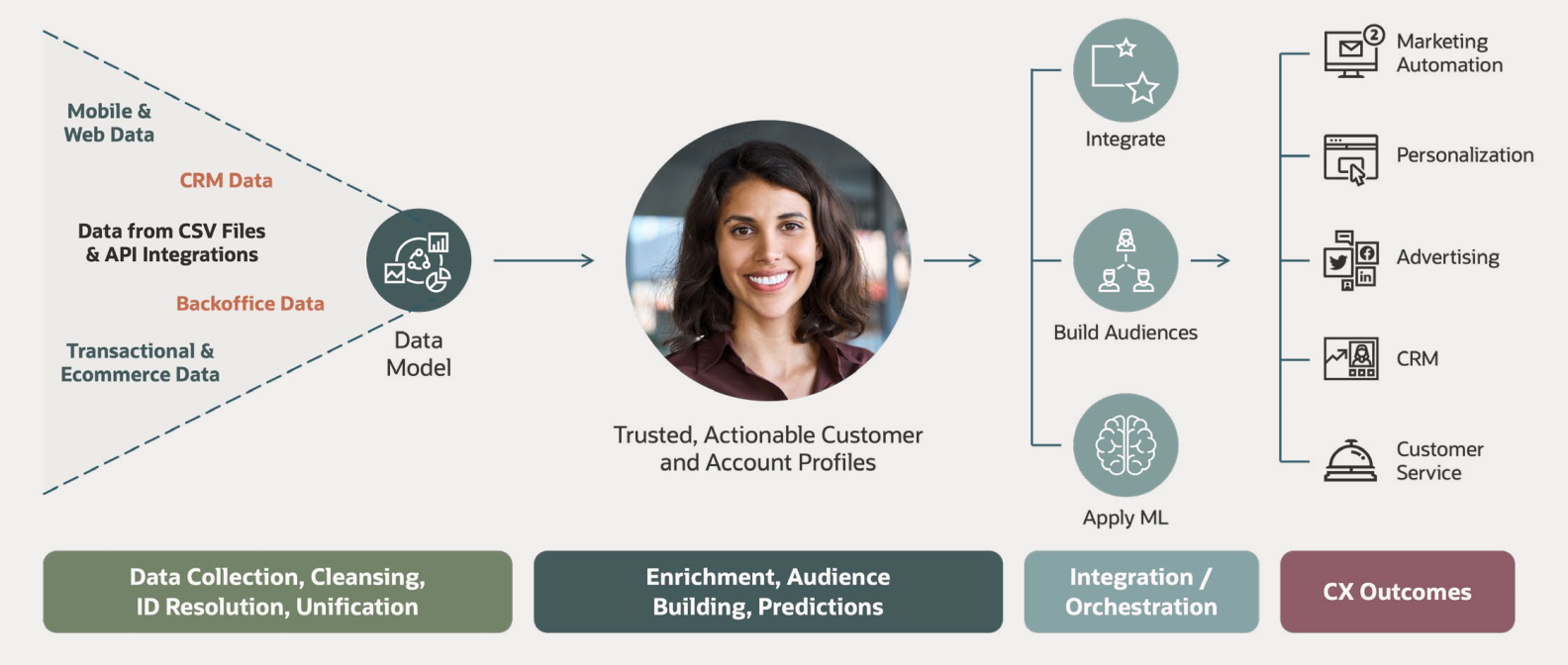
Tại sao CDP của bạn ngày càng chậm?
Thực trạng
Các vendor CEP và CDP đang chào bán sản phẩm với nhiều tính năng trong đó quan trọng là tính năng real-time như tracking, segment, trigger campaign… được xây dựng bằng các công nghệ kỹ thuật mới. Trong đó Database đóng vai trò quan trọng, có thể kể ra như Graph Database, NoSQL hay Schema-Less, họ chê bai Relational Database trước kia là cũ kỹ, chậm chạp.
Tuy nhiên, câu hỏi đặt ra đó là, liệu tốc độ lưu dữ liệu(injestion) nhanh có đồng nghĩa với việc truy vấn thông minh hay chỉ là một nữa sự thật? Bài viết này sẽ bóc tách các vấn đề này về cách thiết kế dữ liệu và vai trò của việc đồng bộ (sync) dữ liệu từ Data Warehouse.
Cuộc chiến
Ở góc nhìn kỹ thuật, từ vendor, họ thích sử dụng Flat Database vì dễ dàng mở rộng với quy mô lớn, dễ dàng nhét bất kỳ dữ liệu nào vào(??? mà thực tế chỉ có thông tin khách hàng – contact data và hành vi khách hàng – event data mà thôi), và tốc độ phản hồi ở mức mili-giây cho các tác vụ (thường là tác vụ đơn giản). Tuy nhiên:
Thực tế cần xem xét:
- Flat Database rất tệ trong các câu truy vấn phức tạp (như complex joins). Ví dụ: “Tìm khách hàng mua sản phẩm A nhưng chưa mua sản phẩm B và tổng chi tiêu > X trong Y ngày gần đây”.
- Relational Database sinh ra để làm việc này. Sự chậm trễ (latency) của Relational Database hiện tại thực ra không đáng kể so với lợi ích về logic cũng như yêu cầu kinh doanh.

Mảnh ghép nào còn thiếu? Warehouse Sync
Tất nhiên rồi, với chỉ dữ liệu thông tin khách hàng (contact data) và hành vi khách hàng (event data) thì không thể nào đáp ứng các kịch bản (use-case) kinh doanh được khi mà dữ liệu phức tạp hơn nhiều:
- Khách hàng có nhiều hợp đồng (policy) trong bảo hiểm chẳng hạn.
- Khách hàng có nhiều tài khoản, nhiều thẻ, nhiều khoản vay trong banking
- Khách hàng có mối quan hệ với contact khác trong doanh nghiệp (B2B)
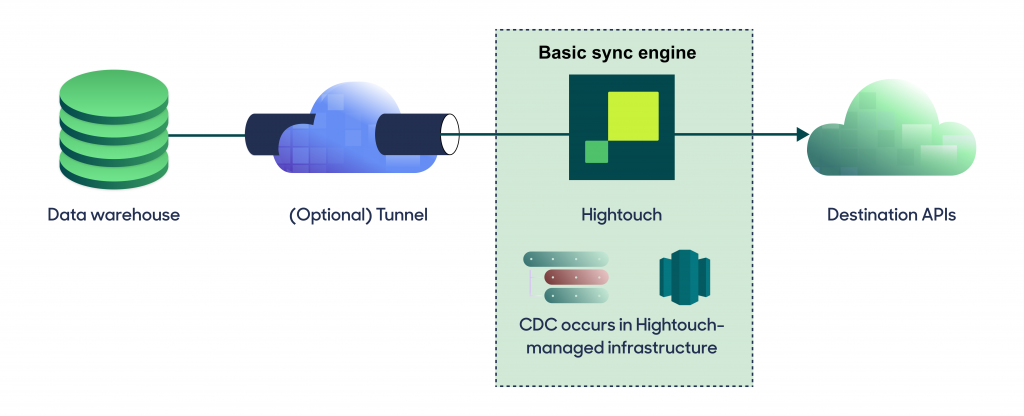
Và thông thường những kiểu loại dữ liệu này được lưu ở dưới core system hay data warehouse, cần phải đồng bộ lên CEP, CDP để sử dụng. Thế là Warehouse Sync được ra đời, là mảnh ghép còn thiếu đó. Điều này giúp Flat Database trở thành kẻ khổng lồ, tất cả việc tính toán phức tạp như Aggregation, Joins… đều do Warehouse xử lý, CDP chỉ có việc nhận kết quả cuối cùng để kích hoạt hành động.
Ví dụ như: Tìm tất cả khách hàng đã mua giày Nike (Event: Product_Purchase, brand: “Nike”) trong 7 ngày qua và có hạng thành viên VIP, và gửi một thông báo giảm giá vào sáng thứ 2 tuần tới. Lúc này sau khi tính toán Data Warehouse sẽ tạo thuộc tính is_Nike_VIP và sync qua CEP, CDP.
Vấn đề phát sinh – Attribute Bloating
Đầu tiên đó là độ trễ, dữ liệu từ các nguồn vào Data Warehouse trễ thì Data Warehouse không kiểm soát được, nhưng các tính toán kia dưới Data Warehouse cũng cần thời gian chạy và cần thời gian đồng bộ sang. Nhưng nếu mức độ ưu tiên của kịch bản (use-case) ở mức vài chục phút có thể chấp nhận được.
Tiếp theo là giới hạn hệ thống CEP, CDP ở vấn đề giới hạn dữ liệu. Thường thì số lượng kịch bản sẽ tăng lên hàng ngày mà các use-case yêu cầu sử dụng. Từ đó việc cần gì để sync nấy là điều tất nhiên, ví dụ last_view_product, last_view_date, last_view_image…
- Profile khách hàng biến thành bãi rác với hàng trăm, thậm chí hàng nghìn thuộc tính.
- Hệ thống chậm đi, chi phí lưu trữ tăng lên (một số hệ thống CEP, CDP cần trả phí để tăng thuộc tính).
- Team nghiệp vụ sử dụng sẽ bị loạn lên khi chọn thuộc tính để lọc dữ liệu cho việc phân khúc khách hàng nếu như không có meta data rõ ràng.
Giải pháp chiến lược
Để xử lý triệt để vấn đề của Flat Database là không dễ dàng, trừ khi đập đi xây lại. Nhưng có thể chữa cháy bằng các chiến lược dưới đây:
- Chiến lược contrỏ – Lookup
- Xây dựng thêm 1 hoặc 2 bảng cố định: Product (Catalog) và Order (Purchase)
- Không cần lưu tất tận tật vào hành vi khách hàng mà chỉ cần lưu Product ID và sau đó lookup vào dữ liệu Product (Catalog) để tìm kiếm dữ liệu tương ứng với Product ID kia.
- Hầu hết việc kinh doanh đều chuyển đổi khách thông qua việc mua hàng hoặc có giao dịch xảy ra, và việc lưu vào Order (Purchase) sẽ giúp việc truy vấn thậm chí cập nhật dễ dàng (như việc cập nhật thời gian, chuyến bay trong ngành Airline).
- Kết quả là Profile trở nên siêu nhẹ, thông tin luôn cập nhật mới nhất.
- Chiến lược gom nhóm – Group
- Thay vì lưu last_view_date, last_product_name, last_product_category thì tổng hợp thành một thuộc tính đối tượng {last_view_date, last_product_name, last_product_category…} trong thuộc tính làm giảm số lượng thuộc tính.
- Chú ý là không phải CEP hay CDP với Flat Database nào cũng hỗ trợ thuộc tính đối tượng (object/json) để lưu như trên. Ngoài ra, việc truy vấn dữ liệu đối tượng để phân khúc khách hàng(segmentation) và sử dụng (personalize) trong campaign là một vấn đề khác lưu ý.
- Ví dụ: một khách hàng có 3 hợp đồng bảo hiểm, mỗi hợp đồng có loại bảo hiểm, ngày bắt đầu, này hết hạn, giá trị hợp đồng… Và nếu hợp đồng thứ 2 sắp hết hạn cần nhắc nhở và bán thêm/bán chéo thì việc truy vấn để xác định khách hàng ngày sẽ được thự hiện như thế nào?
- Chiến lược tái sử dụng – Common attributes
- Dùng các trường chung như common_attribute_1, common_attribute_2… thay vì các tên trường cụ thể theo chiến dịch.
- Lưu dữ liệu vào các trường tái sử dụng này trong một thời gian và sử dụng ở các chiến dịch. Sau đó lại tiếp tục tái sử dụng chúng ở những campaign tiếp theo.
- Chú ý nếu như campaign kéo dài, bạn sẽ gặp rắc rối.
Kết luận & Checklist cho người mua CDP
- Tóm lại:
- Flat Database tốt nhưng chưa đủ, nhưng cần Warehouse Sync hỗ trợ.
- Đừng sync mù quáng, hãy sync thông minh.
- Check list: các câu hỏi sát sườn để hỏi Vendor trong buổi demo tiếp theo:
- Hệ thống xử lý query phức tạp (cross-entity) như thế nào?
- Có hỗ trợ Product Catalog Lookup trong hệ thống không?
- Có hỗ trợ kiểu dữ liệu đối tượng và cách sử dụng (nếu có)?
- Tần suất sync từ Data Warehouse nhanh nhất là bao lâu?
- Dữ liệu được sync từ Data Warehouse sẽ được lưu ở đâu?
- Hệ thống có giới hạn hoặc tính thêm tiền khi số lượng thuộc tính vượt giới hạn?
- vv